Move from detection theater to practical hiring standards
AI for HR gives you a structured process to assess candidate work without relying on flawed detection tools.
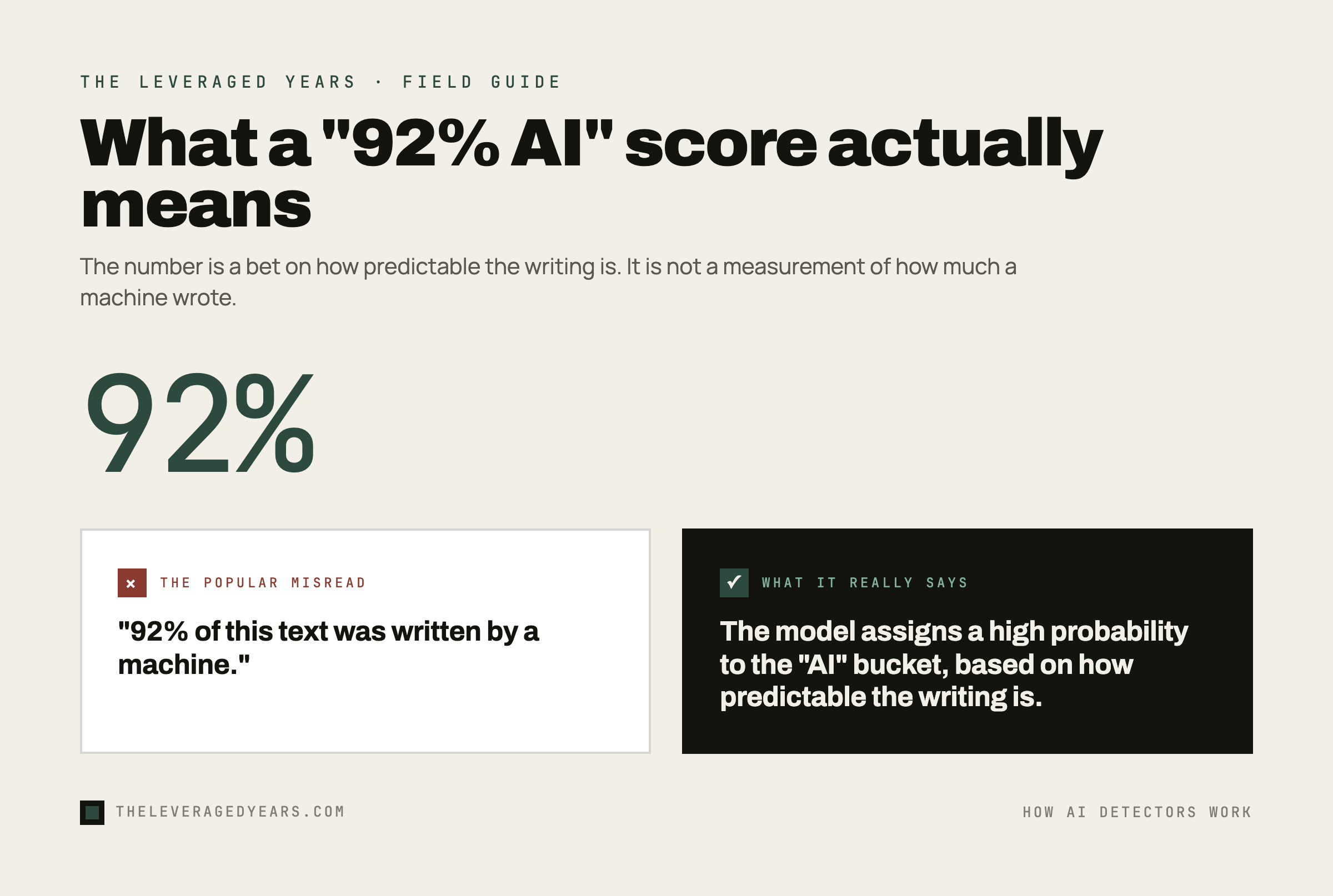
A job applicant sends you a cover letter. Something about it feels too clean. So you paste it into an AI detector, and the tool says "92% likely AI." Now what?
If you treat that number as a verdict, you may be about to reject a strong candidate for the crime of writing carefully. If you ignore it, you may be hiring someone who outsourced their entire application to a chatbot and will outsource the job too. Neither reaction is good, and the reason is the same: most people using these tools have no idea what the number actually measures.
This is worth understanding properly, because the stakes have moved out of the classroom and into hiring, performance reviews, and the daily question of whether the work in front of you is real. So here is how AI detectors actually work, in plain English, and why the honest answer to "can I trust this score" is almost always no.
What the detector is actually measuring
Start with a correction. An AI detector does not read your text and recognize a machine the way you recognize a friend's handwriting. It has no idea what the words mean. It is running a statistical bet based largely on how predictable the writing is, and it expresses that bet as a percentage that looks far more authoritative than it is.
Two ideas do most of the work.
The first is perplexity. A language model like ChatGPT is, underneath, a machine for predicting the next word. Feed it "the cat sat on the," and it will rate "mat" as a very likely next word and "centrifuge" as a very unlikely one. Perplexity is a measure of how surprised a model is by the actual next word in a piece of text. Human writing tends to be surprising. We reach for the odd phrase, the unexpected example, the sentence that takes a left turn. AI writing tends to be less surprising, because the system is tuned to favor likely continuations over unusual ones. So low perplexity, meaning text that a model finds easy to predict, reads to a detector as a signal of machine authorship.
The second is burstiness. Human writing has an uneven rhythm. We write a long, winding sentence packed with clauses, then stop. Hard. Then a medium one to recover. Machine writing tends to be smoother and more uniform, with sentences that hover around the same length and structure. Burstiness measures that variation, and the lack of it counts against you.
On top of features like perplexity and burstiness, many modern detectors add a classifier: a model trained on large piles of human-written and AI-written text, learning the statistical fingerprints that separate the two. This is the part people find ironic, and they are right to. The detector is itself an AI, trained to spot another AI, and it outputs a probability, not a fact. When a tool tells you a document is "92% AI," it is not saying the document is 92 percent machine-written. It is saying its model assigns a high probability to the "AI" bucket based on patterns it learned. That distinction is the whole ballgame, and it is exactly the distinction the percentage is designed to make you forget.
Why the false positives are not a glitch
Here is the part the tool vendors say quietly and the marketing pages skip. False positives, where human writing gets flagged as machine writing, are not a bug that the next version will magically erase. They are a structural side effect of the method: as long as human and AI writing genuinely overlap, the problem stays.
Think about what scores as "AI" under perplexity and burstiness: text that is predictable and uniform. Now think about who writes that way for entirely human reasons.
Non-native English speakers. Research, including a widely cited 2023 Stanford study, has found that detectors disproportionately flag writing by people who learned English as a second language. The reason is simple and brutal. A careful second-language writer tends to use common words, clean grammar, and safe sentence structures, precisely because that is what they were taught and what feels secure. That caution produces low perplexity, which the detector reads as machine writing. You are not catching a cheater. You are penalizing someone for writing English carefully.
Formal and professional writing. The more polished and conventional the prose, the more predictable it looks. A clean executive summary, a tightly structured cover letter, a by-the-book legal paragraph: these are the human documents most likely to trip a detector, because professional writing rewards exactly the uniformity the tool treats as suspicious. The better someone writes in a corporate register, the more they look like a robot to the machine.
Short samples. Perplexity and burstiness need room to show a pattern. A 150-word cover letter or a three-sentence email gives the detector almost nothing to work with, so it guesses, and it guesses with the same confident percentage it would show on a 5,000-word document. The score does not get more honest when the evidence gets thinner. It just looks the same.
How easily the whole thing is defeated
Now flip to the other failure. Even if you accepted the false-positive risk, detectors are trivially easy to evade, which means a confident "human" score tells you almost nothing either.
Ask a chatbot to "write this with varied sentence length and a more casual voice" and you have raised the perplexity and burstiness enough to slip past many detectors. Run the text through one of the "humanizer" tools that exist for exactly this purpose and the score collapses further. Paraphrase by hand, swap a few words, add a typo, and the statistical fingerprint smears. None of this requires skill. It requires a couple of minutes and the knowledge that detectors exist, which is now common among applicants.
So consider the two populations you are actually sorting. The careful, honest, possibly non-native writer who did their own work gets flagged. The person who used AI and spent two minutes covering their tracks sails through clean. The tool is close to backwards: most likely to punish the conscientious and least likely to catch the motivated. A test that fails in both directions at once is not a weak test. It is a coin flip dressed up as science.

This is why the teaching and learning centers at major universities now tell instructors that AI detection software is far from reliable and warn against using it as the sole basis for an accusation. The people closest to the tools trust them the least.
What this means if you hire or manage people
Move this out of the academic argument, because that is where it actually costs you. If you run hiring, lead a team, or review work, "let me run it through a detector" feels like diligence. In practice it often backfires. You are outsourcing a judgment call to a number that cannot support the weight, and you are exposing yourself on two fronts: rejecting good people on a false flag, and waving through the exact behavior you were worried about. From a selection-validity and compliance standpoint, that is the worst of both worlds: an inconsistent signal that is hard to defend if a rejected candidate challenges your process.
The detector is the wrong instrument because it answers the wrong question. You do not actually care whether a candidate used AI to draft a cover letter. Plenty of excellent people use AI to draft cover letters, and the smart ones always will. What you care about is whether this person can think, judge, and deliver when the AI is not in the room. No detector measures that. The good news is that you can, and it is not hard once you stop chasing a fingerprint and start designing for judgment. False flags are only one of the problems with AI worth understanding before you trust a score.
The shift is from detection to design. Stop trying to catch AI in the artifact and start building evaluation that AI cannot complete for the candidate. A take-home that asks for the polished output is easy to fake; a thirty-minute conversation where you ask someone to defend their choices, react to a curveball, and explain what they would change is nearly impossible to fake, because you are testing the reasoning, not the prose. Ask the applicant to walk you through how they would handle a messy, specific situation from your actual world. Ask the employee to explain the tradeoff behind a decision, not just to produce the deliverable. Watch how they revise when you push back. AI can write the memo. It cannot sit in the meeting and own it.
This is exactly what we mean by treating AI fluency as a management skill rather than a threat to police, and it is what we teach inside The Leveraged HR Professional: how to redesign hiring, evaluation, and performance conversations for a workplace where everyone has these tools, so you are measuring the human capability that still matters instead of hunting for a watermark that does not exist. The teams that win are not the ones with the best detector. They are the ones who stopped needing one.
A practical note for the other side of the desk, too. If you are the candidate worrying that your own careful writing will get you flagged, the answer is not to dumb it down to fool a machine. The fix is to use the tools well and stay in command of your own material, which is a different skill than prompt-stuffing. We walk through that in our guide to writing resumes and applications with AI without sounding like a robot, and it pairs with the broader case for judgment as the skill that AI cannot replace. If you want to see the full range of where this fits your role, you can also browse all of our courses.